

Abstract
Transformers are machine learning models with sequence-to-sequence architecture for transforming a given sequence of elements into another sequence. BERT is a powerful Transformer-based machine learning model for state of the art (SOTA) NLP applications that have outperformed previous models in different benchmark datasets. In this study, a successful classification task on Customer ticket dumps into predefined labels is reported using a pre-trained BERT model with very few epochs of fine-tuning.
Introduction
Enterprise Information Technology (IT) Service Management (ITSM) has become an essential component in the transformation of IT applications and infrastructure components into IT Services (ITS). While efficient and best ITSM practices are critical to operational efficiencies, the complexity of IT environments is continuously increasing along with the dependencies on most business processes. ITS availability and stability thus form the part of key performance indicators (KPIs) for the success of ITSM efforts. In addition, such ITSM best practice frameworks add value when the ever-increasing cost is optimized too. Data-driven techniques come in handy by providing predictive and prescriptive solutions.
ITSM comprises a dedicated team of IT experts handling the issues faced by the stakeholders. The user in trouble raises a ticket requesting a solution for a problem that can be an issue or query. Queuing system in places assigns a ticket number, and the user waits until the right ITSM expert addresses it. This typically consumes time in days and has the chance of risking a complete halt of critical business processes occasionally. Automation and predictive and proactive actions are necessary to avoid such critical situations. Tickets are typically unstructured logs describing the customer's issue typically rising to a huge number, and categorizing them becomes a difficult task. Support tickets are of High volume and unstructured rich text in nature.
Tagging
Tags are labels created by the support team on every customer query raised. Such tagging helps transform the unstructured queries into structured data, which aids in quick understanding of underlying customer issues and develops solutions to align customer support and product teams.
Tagging challenges
A manual ticket tagging is by keyword extraction and holds good for cases as far as rules are mapped with it. Disadvantages include the impossibility of covering every rule, inconsistencies in tagging with missing context, and the inability to adapt to new rules.
Automated Ticket Tagging
Automation of ticket tagging is possible by applying machine learning techniques. This enables customer data retention and allows analyses with structured data. Such high-level visibility obtained by automated tagging aids in understanding the evolution of customer issues over time and aids in developing data-driven strategies. Advantages include better customer support and turnaround time, avoiding back-and-forth routings. Reduced manual error and turnaround time results in a better ROI of customer support ticketing tasks.
Machine learning (ML) based Natural Language Processing (NLP) approaches to handle this challenge by tagging the tickets as a first step, which then can be assigned to the expert based on priority and type.
Tags can be mapped accordingly with the existing issue process/sub process categories listed which are supervised learning. Another approach would be an unsupervised approach where the tickets can be clusters or topic modeling.
Example Tags would include but are not limited to
-
Type of issue
-
Location
-
Priority
-
Sentiment
NLP Based Tagging
At Inspirisys, We have dedicated our efforts to building in house solutions ourselves.
The NLP based tagging engine preprocesses the unstructured log messages and tags every support ticket. The NLP model is customized and can be trained to understand the business context unique to the customer. With the option of customizability to any NLP based tagging algorithms, we have deployed BERT, which stands for Bidirectional Encoder Representations from Transformer
![]()
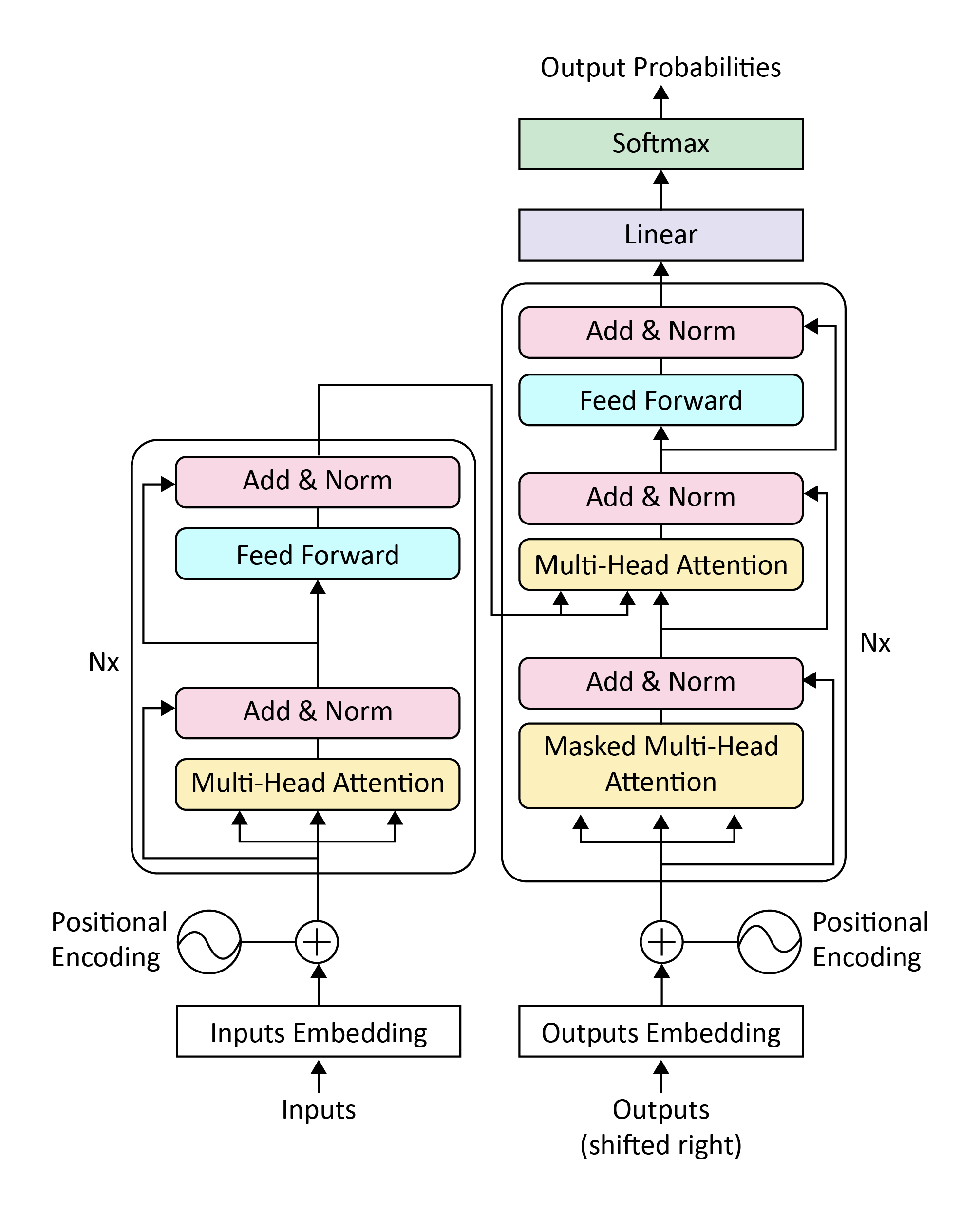
BERT pre trains deep bidirectional representations from unlabeled texts and each word are contextualized bidirectionally. Context learning is accomplished through Transformer's attention mechanism, which learns relationships between words in a text. A typical transformer consists of an encoder reading input text and a decoder to produce a prediction for the task where the task could be a language modeling, Translation, or Classification. The input to the encoder for BERT is a sequence of tokens (words), which are first converted into vectors and then processed in the neural network. Pretrained text encoders are typically sequences of tokenized texts, where the sequences form the contextualized representation of the input text. The length of the input text is an inherent factor for all the inherent matrix multiplication operations. The shorter the length of the input, the sooner the training and inference and the more the improvement in the accuracy can be expected.
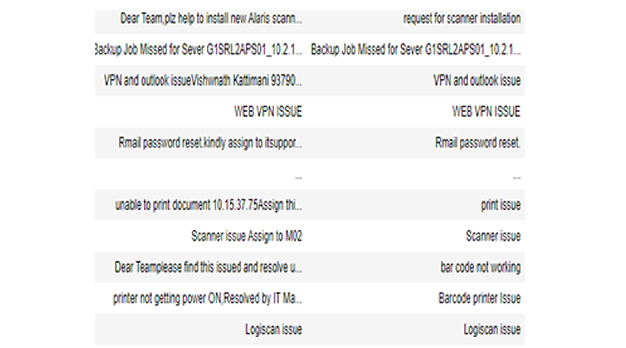
A typical customer service ticket comprises huge natural language text as shown below in the example. This makes it necessary to filter out the insignificant (irrelevant to the context) words and pass them on to a fine-tuned BERT model implementation. As seen from the example figure below, the first line contains information about a particular scanner and a masked IP address of an End-user system.
BERT models are available pre-trained, on a large corpus, which can be used for our task objective, which is ticket classification by adding a few extra layers at the end. In practice, we could use the output from the [CLS] token for the classification task. So, the whole architecture for fine-tuning gets simplified like this.
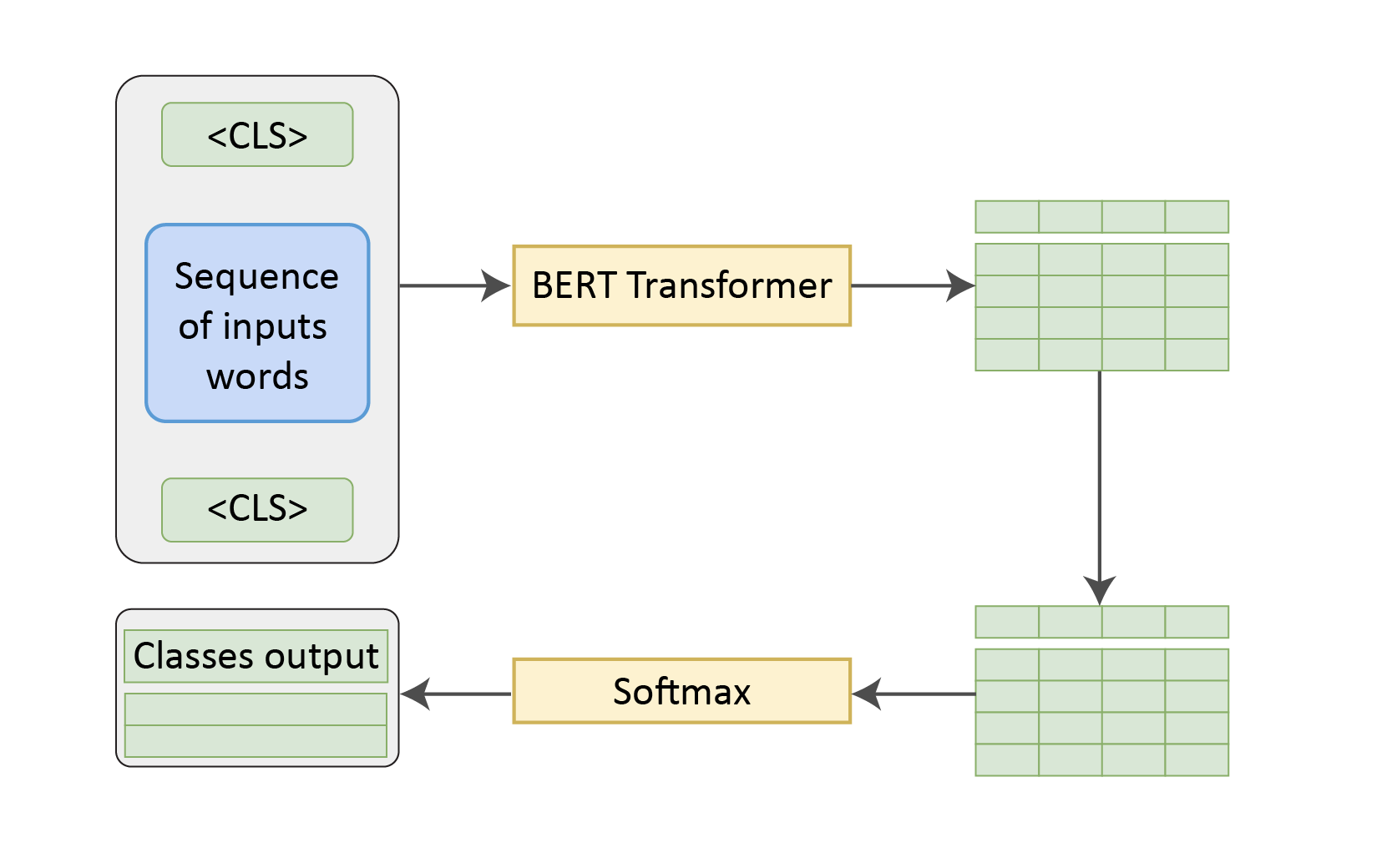
Objective
-
To develop a fine-tuned BERT multiclass classification model to tag a given service ticket.
-
To build a demo application endpoint to serve the model predictions
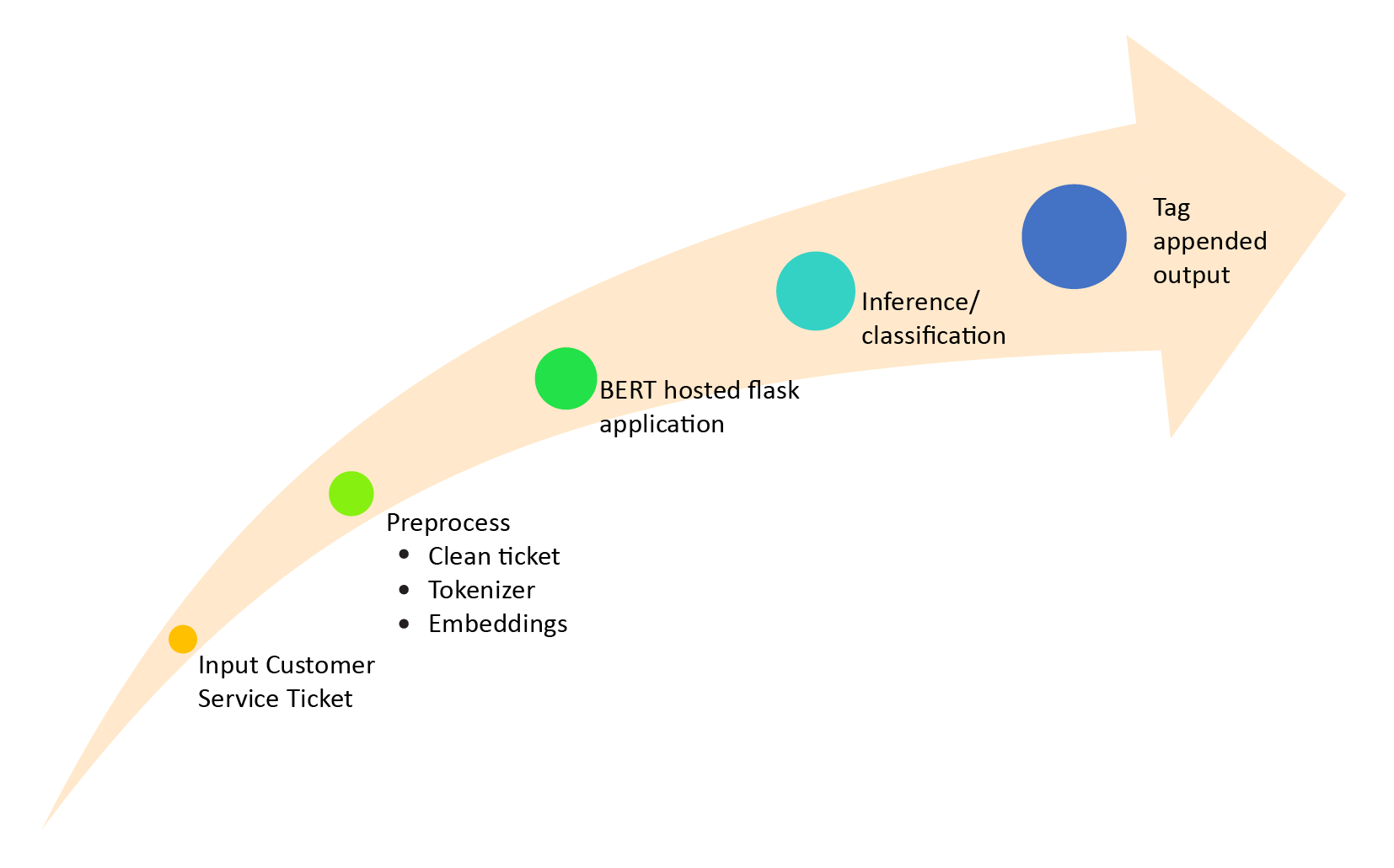
Implementation
BERT model
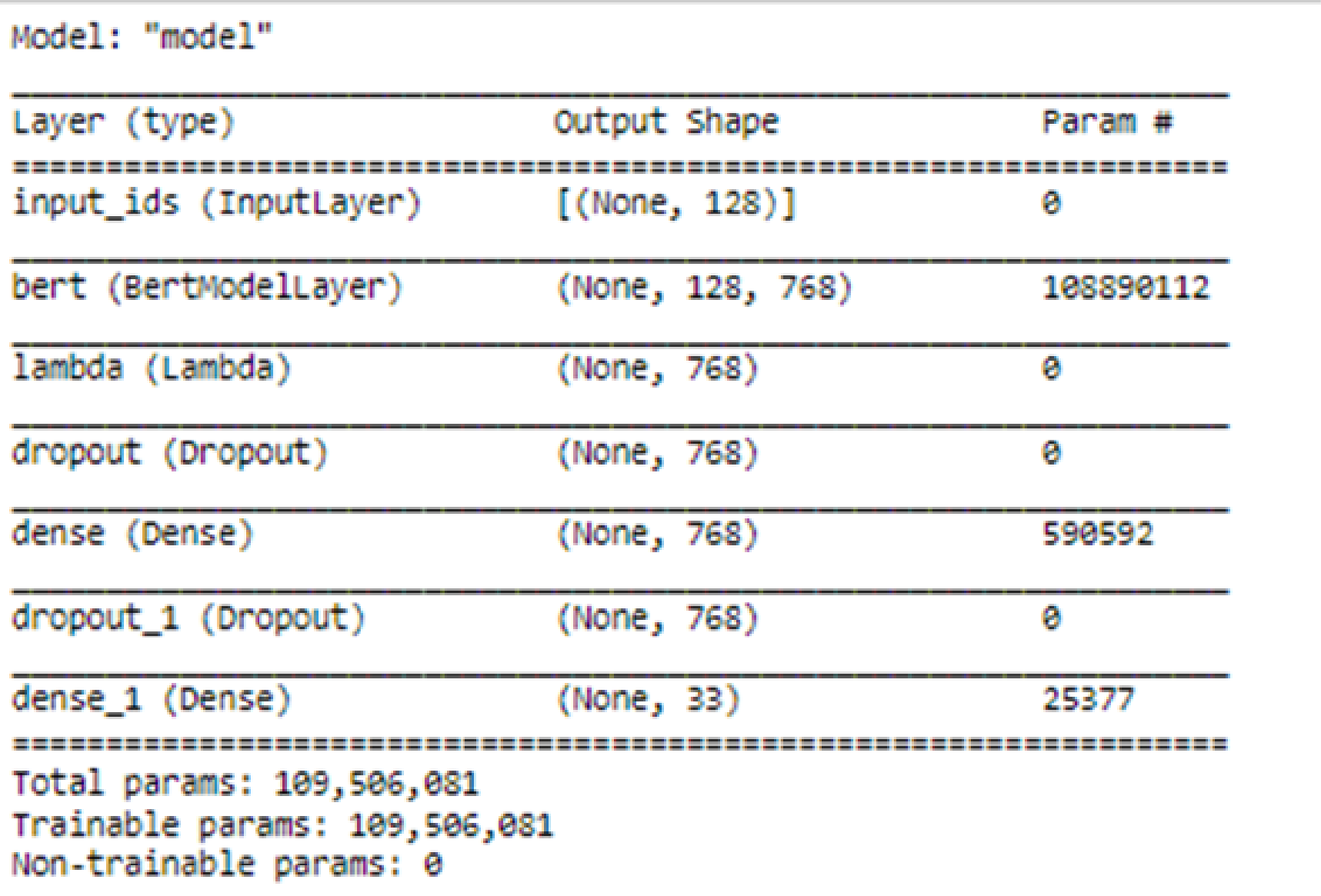
We took a base model BERT-Base, Uncased named "uncased_L-12_H-768_A-12", where L denotes layers, H denoted the number of hidden layers and A stands for the number of attention-heads initially. Max sequence length was kept at 128.
Preprocessing
Pre-processing pipeline comprises decision making on the choice of data to be included in the training. A large number of tickets that had been tagged in the 'Others' Category or the 'Miscellaneous' Category have been removed. In addition, the classes having very few observations leading to class imbalance have also been removed. Classes having less than a hundred observations have also been removed as they may form the part of outliers in a normal distribution. Classes having more than two hundred observations are restricted to two hundred.
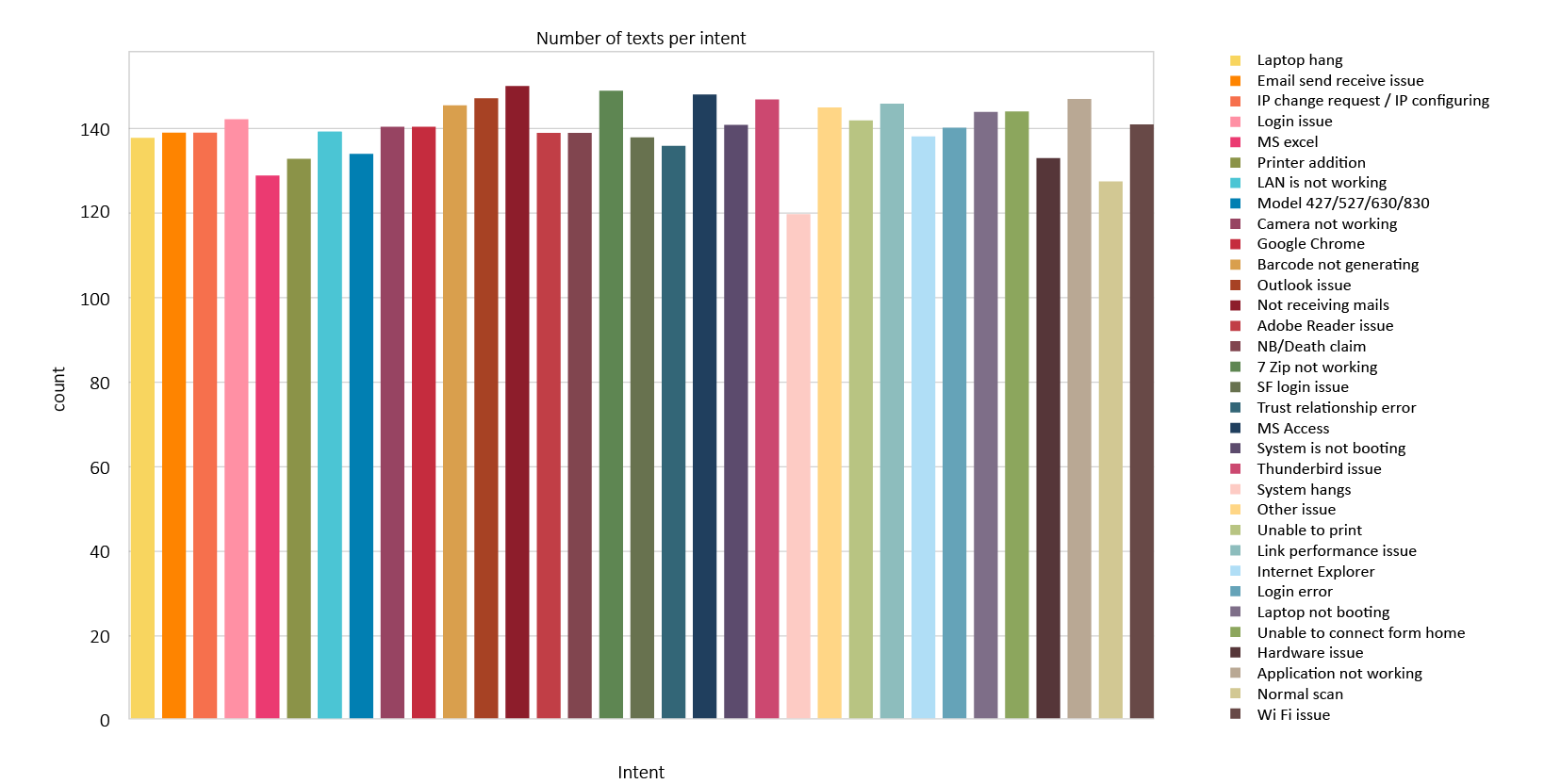
Cleaning
 As the length of the sequence in BERT is a major constraint in contextual learning, further cleaning has been performed by removing conjunctions, prepositions and common words. Common words examples in this context include "dear, pls, assign, itsupport" etc. A dictionary of new stopwords along with existing nltk library stopwords has been developed. Privacy sensitive information like Name, designation, proper nouns, location, IP addresses, telephone contacts etc. were also removed.
As the length of the sequence in BERT is a major constraint in contextual learning, further cleaning has been performed by removing conjunctions, prepositions and common words. Common words examples in this context include "dear, pls, assign, itsupport" etc. A dictionary of new stopwords along with existing nltk library stopwords has been developed. Privacy sensitive information like Name, designation, proper nouns, location, IP addresses, telephone contacts etc. were also removed.
130 classes were considered with the following hyperparameters of 100 epochs, with batch sizes varying from eight to sixteen with different BERT models (12/768: BERT-Base, 8/512: BERT-Medium, 4/512: BERT-Small and 4/256: BERT-Mini). The different models showed the tradeoffs between performance and accuracy as expected. The BERT 12/768: BERT-Base gave more accurate results (93 percent during training and 84 percent during testing) than others while taking more time for training.
Hosting Model
The model is hosted as a flask application which can run on both Linux and Windows environments.
A simple index.html file is placed in the /templates folder. This page provides the option of uploading a CSV file for input and another CSV output file with the results appended to the input.
- A new Flask instance with the argument __name__ for finding index.html on the template folder.
- Using the URL routing decorator (@app.route('/')) the home function is executed which in turn renders the index.html file located in the template folder.
- The data set is accessed inside the predict function and preprocessing, predictions and model saving are performed.
- The post method is used to transport the data to the server and results are fetched using the GET method.
- Application is run by the run function and the script is directly executed by the Python interpreter.
Conclusion
This exercise successfully built a classification model for IT service tickets by fine-tuning a BERT model with very few epochs. The model was able to classify tickets into appropriate subcategories. Fine-tuned model was created using the TensorFlow package, and it has been hosted as a flask application with the model making successful predictions. This is a first step towards building a predictive analytics framework where further steps would be priority tagging and automatic ticket assignment based on availability and experts. In addition, integration with an open-source BI tool for visualization dashboards would provide necessary inputs for decision making. While BERT models provide options of multiple extensions like generating QA from the ticket dump texts, missing value predictions to generate and understand the accurate context for ticket dumps, other machine learning-based regression models for predicting the resolving time for a given ticket from historical records, predicting the possibility of a type of customer tickets for an instantaneous time are possible extensions as predictive analytics services. From the analytics perspective, the next step of automated priority assignment tickets and automated solutions for low priority tickets would be of great value additions.
Reference
https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
https://github.com/google-research/bert




