
Quick Summary: Large Language Models (LLMs) stand as significant players in the tech arena. Delving into their operations proves to be intriguing. This article serves as an introductory guide, shedding light on LLMs, their variations, prominent examples, and practical applications.
Imagine a huge library filled with an endless collection of books, each carrying a vast amount of information. In this spectacular storehouse, picture the Librarian as our Large Language Model - a digital curator with supreme abilities. When you pose a question, this model, like the Librarian, examines its extensive collection of information to provide not just comprehensive but also insightful answers.
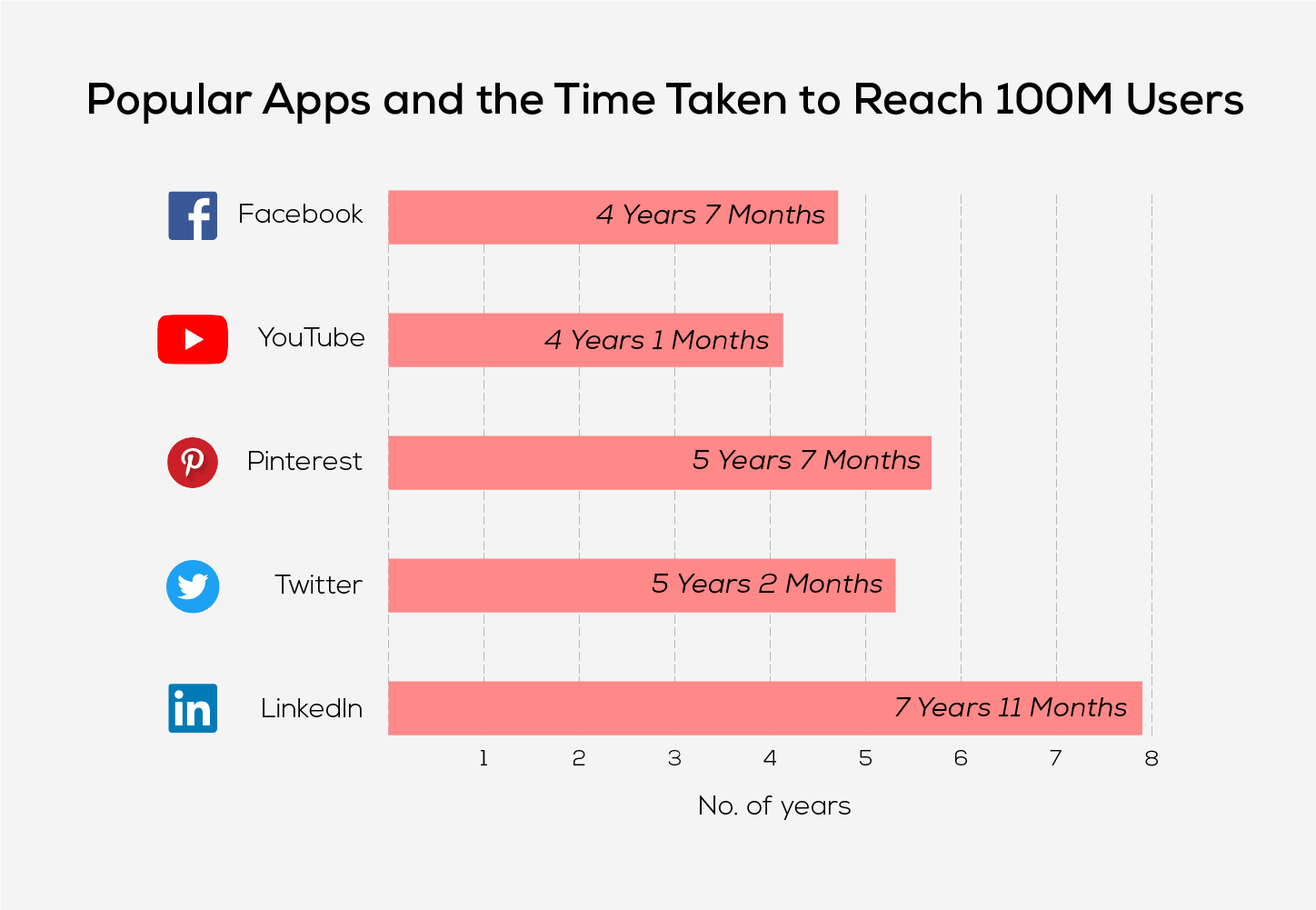
Today, the world uses one such Large Language Model (LLM), i.e. ChatGPT. OpenAI took the digital world by storm with the release of its ChatGPT model on November 30, 2022. This modelredefined the conversational landscape with its intense knowledge demonstrating an outstanding capability to engage in rich and dynamic discussions. Just within a few days of its initial release, the users flocked to interact with this model. ChatGPT gained 100 million users in just 2 months, surpassing Instagram and TikTok, both of which reached this milestone in 2.5 years and 9 months respectively.
In this article, we will delve deeper into understanding the Large Language Models (LLM), exploring how they work, their limitations and applications.
What is a Large Language Model?
Large Language Model is one such AI that can mimic human intelligence. It employs a statistical model to analyse vast amounts of data, learning patterns and connections between words and phrases. This capability enables the generation of content, such as essays and articles, in the style of a specific author or genre.
These models are typically based on Transformer architecture and carry a large number of parameters often in billions or trillions enabling them to capture extensive data. Large Language Models like GPT4 possess immense capabilities to work like virtual assistants. From drafting emails to blog creation and even teaching a foreign language, they are equipped to perform a wide range of tasks.
Large Language Model Vs. Generative AI
LLMs are a specific type of artificial intelligence model designed for natural language understanding and generation. LLMs excel in processing and generating human-like text across various tasks, such as text completion, language translation and conversation.
Whereas Generative AI is a broader term that covers AI models and techniques capable of generating new content, not limited to language alone. Text, code, images, video and music can also be generated through Generative AI. Midjourney, DALL-E and ChatGPT are some examples of Generative AI.
LLMs are a subset of Generative AI, stressing natural language, understanding and generation. It offers diverse forms of content beyond the text.
Understanding the Architecture of Large Language Models
Large Language Models are a type of neural network comprising multiple layers and interconnected neurons arranged hierarchically. They are specifically tailored for Natural Language Processing tasks.
The early large language models were built based on recurrent neural networks. When presented with the sequence of texts, it could predict subsequent words in the sequence. As it subsumes knowledge from its own generated inputs, it was deemedrecurrent. This means the output it generated was fed back into the network to enhance its future performance.
What is a Transformer Model?
A transformer model is the most common architecture in LLMs. It understands and interacts like a human. There are two main parts to it; one is the encoder, and the other is the decoder. It processes the data by tokenising the inputs. Then it uses some mathematical equations to understand the connection between the tokens. It starts spotting patterns just like how a human would analyse it.
Self-attention mechanism is a distinct feature of this model, which makes it even smarter. This ability enables it to quickly grasp and understand things by simultaneously attending to different parts of words. This self-attention power enables the Transformer model to understand the sequence in a sentence or understand the meaning in the entire passage.
How Does the Large Language Model Work?
A Large Language Model uses a Transformer Model architecture that processes input through encoding and decoding stages to generate an output prediction. However, before it can receive text input and provide output predictions, the large language model undergoes training to acquire general capabilities.
-
Pre-Training: Large Language Models are pre-trained using large textual datasets containing a varied range of texts from the internet like books, articles and websites. These datasets comprising trillions of words significantly affect the performance of the model. During this phase, the Large Language Model undergoes unsupervised learning from all the provided datasets, without any specific guidance. The pre-training stage is the most expensive and time-consuming stage of building LLM. Here LLMs not only learn to understand different words, their meanings and the relationship between them, but also the context in which these words are used.
For example, It can understand if the word ‘lie’ meant ‘not true’ or ‘a resting position’. It can also predict subsequent words in partially complete sentences like ‘The adventurous explorer ventured deep into a mysterious_____’. If OpenAI’s GPT model had to predict this it would suggest words like ‘cave’, ‘forest’ or ‘landscape’ based on its understanding of context and common patterns.
A method like Masked Language Modeling is used by Google that trains BERT (LLM) to guess randomly blanked words in a sentence. For instance, ‘The ___ explorer ventured deep into the mysterious forest’.
- Fine-Tuning: Although pre-trained models seem extraordinary, they are not inherently experts in specific tasks. Fine-tuning the Large Language Model involves training the pre-trained model to master a particular task. This is a process where the pre-trained model is trained in sentiment analysis, language translation, or answering questions related to specific domains.
This process helps LLMs to reveal their full potential and tailor their capabilities to specific applications.
- In-Context Learning and Prompt Tuning: In-context learning involves adapting and learning from the context of an ongoing conversation or interaction. Let us understand this with an example.
For instance, if the user asks, “What’s the weather like today?” the model may respond by saying, “The weather is sunny and warm.” If the user then asks, ”You think I must carry an umbrella?” the model may respond, “Since the forecast is clear, there is no need for an umbrella today.”
Whereas, in Prompt tuning, the model is adjusted and trained with specific prompts or instructions to improve its performance on specific tasks or in specific contexts. For instance, the user may instruct by saying, “Summarize the following content”, or “Translate the content in French”.
Both aspects contribute to enhancing the performance of LLMs in dynamic interactions.
Types of Large Language Models
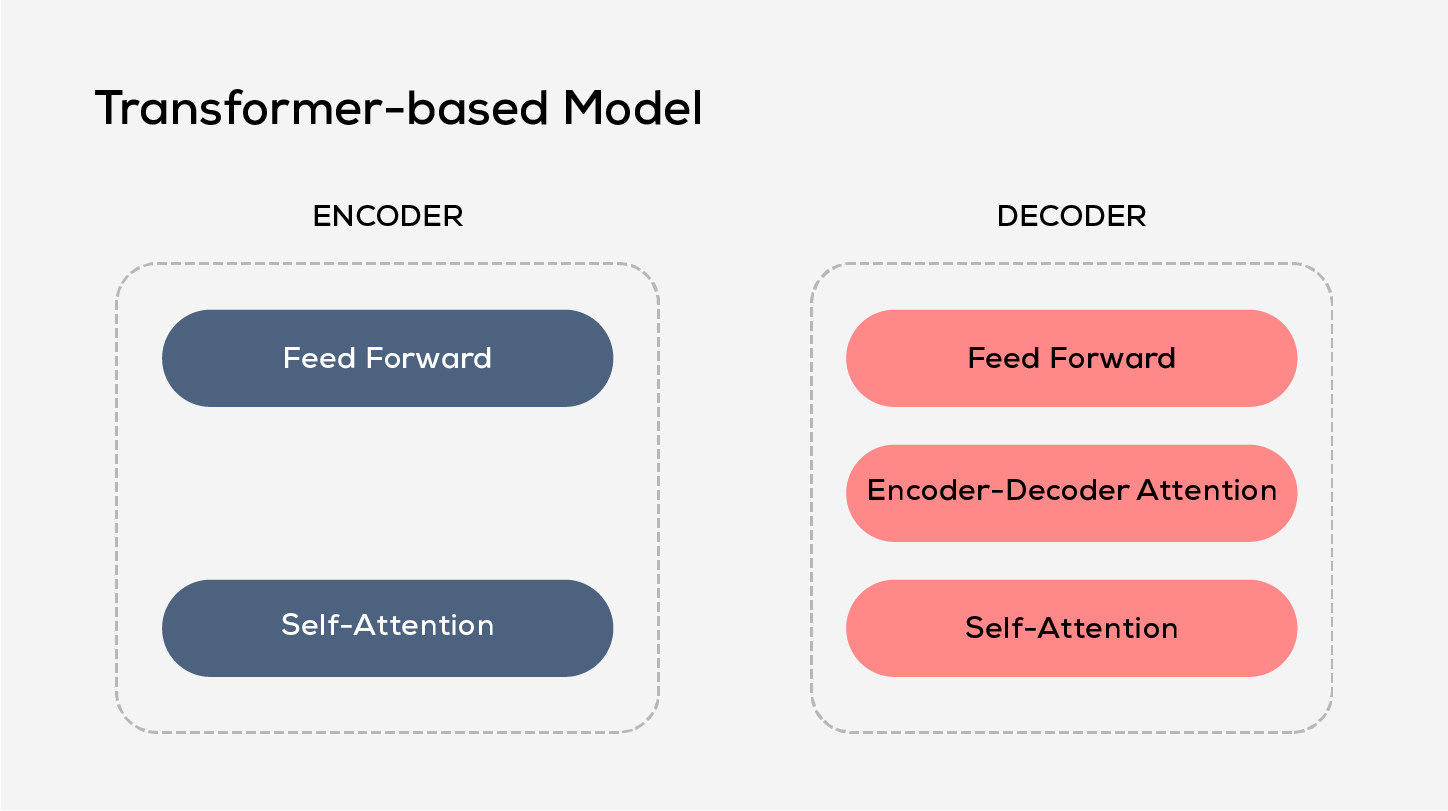
- Transformer-based Model: Transformer language models operate through a combination of self-attention mechanisms, positional encoding and multilayer neural networks to process and generate textual content. The self-attention mechanism is the primary component in the Transformer architecture. It establishes a weighted representation of the input sequence and considers relationships among its various elements. This mechanism enables the model to grasp long-range dependencies and contextual information effectively.
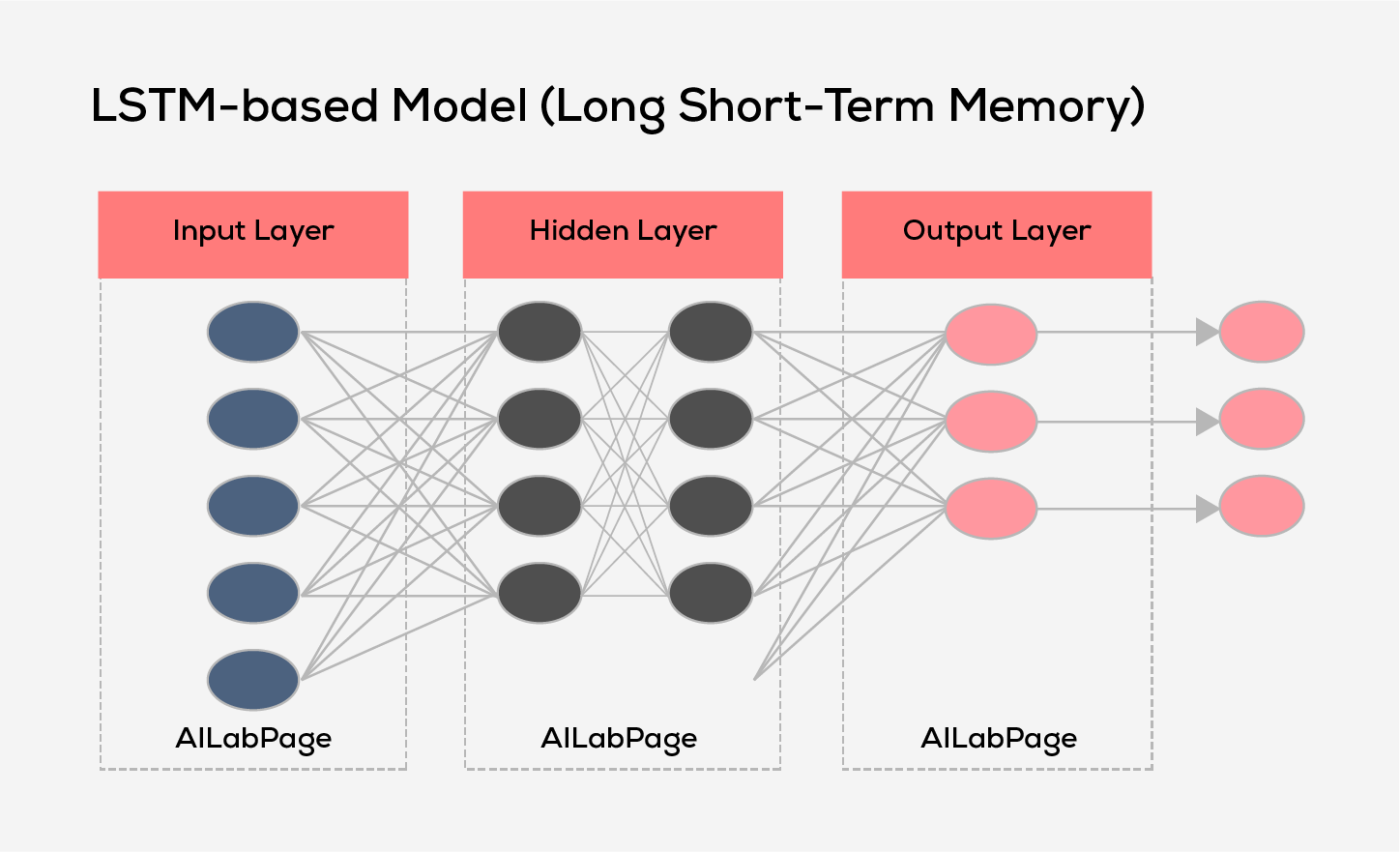
- LSTM-based Models (Long Short-Term Memory): LSTM-based model is a type of recurrent rural network (RNN) architecture in the field of deep learning. They are designed to handle and learn from long-term dependencies in sequential data.
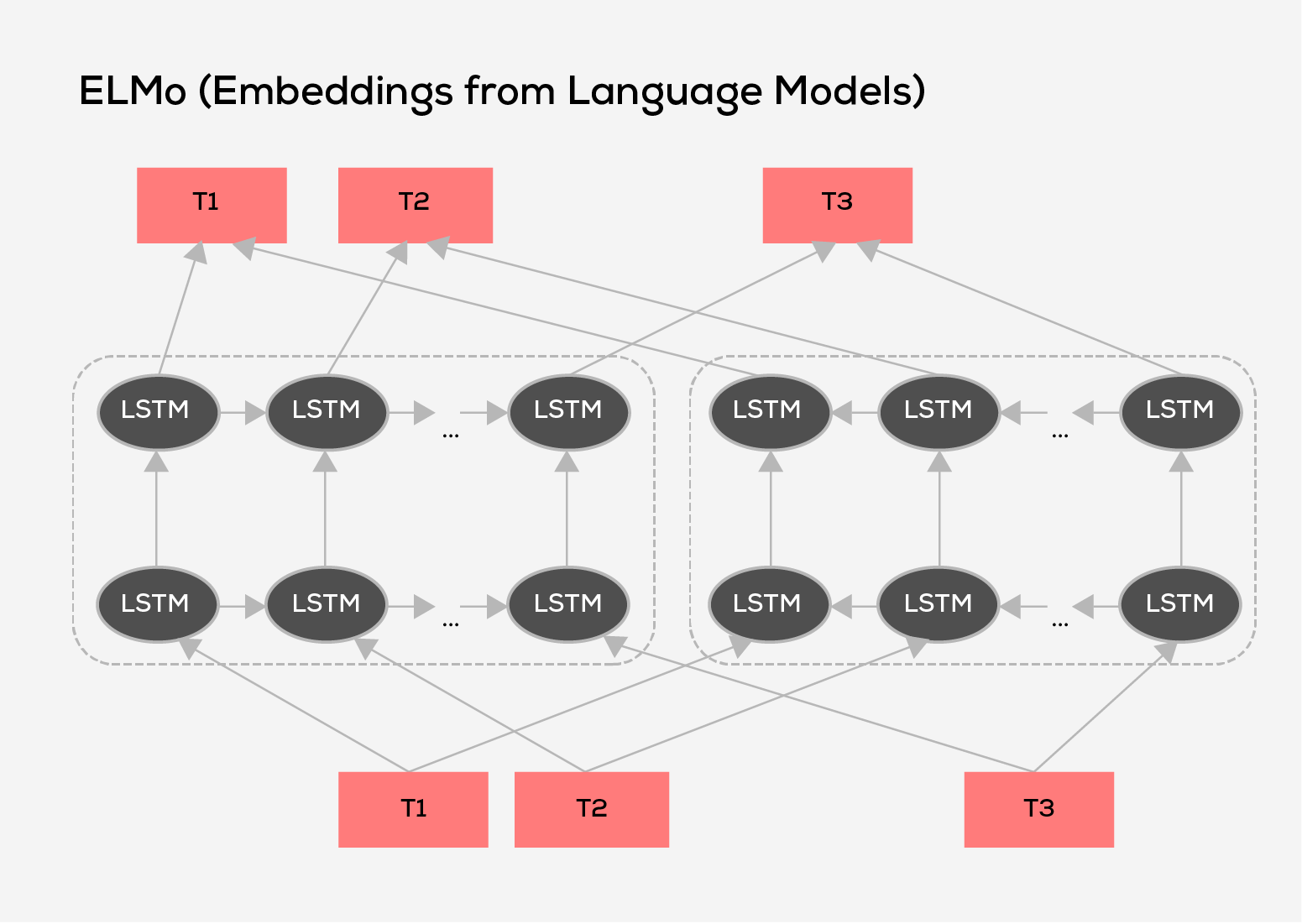
- ELMo (Embeddings from Language Models): ELMo is a framework developed by the Allen Institute for AI. It stands as a substantial language model generating contextualized word embeddings. The use of ELMo embeddings has proven that it improves the effectiveness of various Natural Language Processing (NLP) tasks by providing context-specific insights.
While ELMo is among the well-recognized large language models, the NLP research community features a range of diverse models and innovative variations, with new models and techniques constantly being developed.
Popular Language Models
Everyone is familiar with and has used ChatGPT, however, several LLMs have gained popularity and taken the world by storm with their impressive performance.
The LLMs include:
- GPT3: Developed by OpenAI, Generative Pre-trained Transformers, or GPT-3, is among the most well-known and powerful autoregressive large language models. With an astounding 175 billion parameters, it can generate highly meaningful and contextually relevant text. It is also flexible for fine-tuning, allowing customization for specific tasks or industries. This model finds applications in natural language understanding, translation, question-answering and many more.
- PaLM: The Pathways Language Model (PaLM) by Google, is transformer-based and is adept at handling tasks such as common-sense and arithmetic reasoning, joke explanation, code generation and translation.
- BERT: Google has also developed the Bidirectional Encoder Representations from Transformers (BERT) model, which is a transformer model designed to comprehend natural language and provide answers to questions.
- XLNet: As a permutation language model, XLNet departs from BERT by generating output predictions in a random order. It evaluates encoded token patterns and predicts tokens randomly, deviating from the sequential order employed by BERT.
- T5: Text-to-Text Transfer Transformer is a versatile language model that seamlessly integrates autoregressive and autoencoding approaches. It is capable of handling a wide range of NLP tasks by framing them into text-to-text problems.
Large Language Model Use Cases
Large Language models have a variety of applications across various domains and industries. The following are the most common use cases.
- Text Generation: This is the most common feature of a large language model. These models can generate meaningful content for relevant passages in a sequential manner. Users can benefit from them for various other purposes like content generation for blogs, websites, brochures, etc. It also aids in the completion of missing information in documents. Furthermore, they can be fine-tuned to create domain-specific content making them adaptable and versatile for various industries.
- Text Summarization: Large Language Models (LLMs) possess a unique ability to condense vast content, extracting key points and summarizing them for the user. Utilizing LLMs for condensed or summarized text saves considerable time and effort, particularly in the legal, health, and financial sectors. Researchers can leverage this ability of LLMs and gain extensive knowledge and stay updated with the latest information.
- Sentiment Analysis: To comprehensively grasp the emotional tone or attitude expressed by the user, large language models utilise sentiment analysis. In this process, the language model analyses the text and classifies if the given expression is positive or negative or neutral. This particular feature is highly beneficial for organizations in comprehending their customers' feedback.
Experience a sentiment-based Predictive Analytics platform from Inspirisys, that is designed to elevate your strategies, providing valuable insights that drive success. Explore the power of data-driven decision-making and remain at the forefront of the industry.

Ready to Revolutionise? Explore SocioMentis now!
- Chatbots and Conversational AI: Generating human-like text makes large language models more endearing, especially in an interactive set-up, where a Chabot responds to the user who wants to ask or inquire about a specific issue. These customer support Chatbots make the process hassle-free and provide the required information to the user. This technology can be further applied to create virtual tools, educational tools and many more.
Challenges in Large Language Models
Although everything seems promising about the Large Language Model, there are some challenges to it, which the user should be aware of.
- Hallucination: This is a phenomenon when LLM produces a false output. Although it may exhibit coherence and contextually relevant content, it may not be accurate. It can be a matter of concern, especially in applications where factual correctness is paramount, as the language model may unintentionally generate misleading information. Since it fails to entirely interpret human meaning, the result is referred to as ‘hallucination’.
- Security: There is a high risk of misinformation if users with malicious intentions reprogram AI for selfish motives or spread wicked ideologies. If it is not managed or monitored properly, it may lead to the disclosure of private information, phishing scams and many disastrous activities at a global level.
- Potential Bias: Since the model extracts information from various datasets, it also perpetuates the biases present in it. These could result in cultural, demographic and social biases in the model’s output. Efforts to enhance transparency, refine training datasets and implement ethical guidelines can help LLMs to positively contribute to varied applications and mitigate risks and discrimination.
- Computational Resources and Training Time: The process of training large language models is resource-intensive and requires powerful hardware infrastructure and substantial processing capabilities. Furthermore, the duration of the training phase extends over weeks or months, which poses a major barrier for organizations that have constrained resources, as high computational requirements can be expensive and time-consuming.
LLMs Shaping Tomorrow’s World
In summary, the introduction of ChatGPT has thrust Large Language Models (LLMs) into the limelight, sparking heightened interest and demand across numerous industries. While this signals exciting technological progress, there are valid concerns about the potential displacement of jobs in certain sectors. Despite the ongoing uncertainty surrounding the future of AI and LLMs, their capacity to enhance productivity, streamline operations, and drive innovation across diverse fields holds immense promise, presenting opportunities for improving the human experience.
Frequently Asked Questions
1. What is Deep Learning?
Deep learning is a type of artificial intelligence that mimics the processes of the human brain. It allows computers to analyze complex patterns in various data types, such as images, text, and audio, resulting in precise insights and predictions.
2. What are the layers of LLM Architecture?
Large Language Models (LLMs) typically comprise several layers, including feedforward, embedding, and attention layers. These layers work collaboratively on embedded text to generate predictions.
3. What is a Recurrent Neural Network?
A Recurrent Neural Network (RNN) is a type of neural network designed to handle sequential data by retaining information from previous inputs. It's commonly used in tasks like speech recognition and language modelling.
4. What is the difference between NLP and LLM?
LLMs are a subset of NLP techniques. While LLMs focus on building large-scale language models capable of understanding and generating human-like text, NLP involves a wider range of techniques for processing and analyzing natural language data, including tasks like sentiment analysis, machine translation, and named entity recognition.
5. Give some examples of transformer-based LLMs
ELECTRA, ALBERTA, DeBERTa , RoBERTa are some of the transformer-based models.




