

Quick Summary: ChatGPT, powered by OpenAI's GPT models, stands out as a widely recognized tool utilizing LLM technology. As a result, numerous other LLMs have emerged. Although closed-source models often boast structured support and polished features, they contrast with the transparency and customizability of open-source alternatives. In this article, we delve into the world of open-source LLMs and their advantages for businesses and individuals. Additionally, we provide a curated list of the top ten open-source LLMs.
Large Language Models serve as a backbone to numerous AI tools and features, wielding the ability to comprehend and generate human language by processing extensive data sets. They operate on neural network architectures, allowing for versatile training in Natural Language Processing (NLP) tasks like content generation and translation. What's interesting is that many of these LLMs are open-source, that foster collaboration and innovation. This accessibility enables automating crucial business tasks such as customer support chatbots and fraud detection, while also fuelling advancements in diverse fields like vaccine development. Beyond business applications, LLMs strengthen cloud security, refine search functionalities and enhance data analysis capabilities, promising a future of streamlined operations and enriched insights across industries.
Understanding Open-Source LLMs
An LLM which is freely available to everyone is known as open-source LLM. This means that they provide publicly accessible training datasets, architectures and weights that promote transparency, reproducibility and decentralization in AI research. Any person or business can modify and customize as per their requirement. The opposite of open-source LLM is the closed-source LLM, considered a proprietary model owned by a single person or an enterprise. OpenAI’s GPT series of models is a popular example of a closed-source LLM.
The Best Use Cases of LLMs
Here are some key capabilities of LLM.
- Research: LLMs can be useful in research as they help gather relevant information from large datasets.
- Content Creation: Several LLMs have made content creation easy, not only do they help in generating new ideas, but they can also contextually generate content as per the requirement of the user.
- Sentiment analysis: LLMs are excellent at identifying the opinions of the users through feedback, social media, etc.
- Chatbots: LLMs can be finetuned and customised for specific chatbot applications, especially for customer support, enabling intelligent interactions between the user and the virtual assistant.
- Translations: LLMs can improve the accuracy and speed of language translation by understanding the intricacies of different languages and performing natural translations.

How to Choose the Right Open-Source LLM for Your Business
There are certain key aspects that one needs to consider before choosing a suitable open-source LLM for their business.
- Cost: Although the models are free, it is important to evaluate the costs of hosting, training and resources. Complex and larger LLMs may require increased data storage, processing power, infrastructure and maintenance expenses.
- Performance: Better performance enhances the user experience and task effectiveness. Therefore, it is essential to evaluate language fluency, coherence and context, as it helps in attaining a competitive advantage.
- Data Security: This is a crucial element to consider, especially when handling sensitive or PII (Personally Identifiable Information) data. The RAG technique is critical for effectively restricting permissions and access to data.
- Accuracy: It is vital to assess the capabilities of different LLMs for specific tasks based on your needs. Determine whether these models are tailored domain-specific or can be fine-tuned by RAG.
- Quality of Training Data: The quality of the data has a direct impact on the output, making it fundamental to assess the data used to train the LLMs. Using custom data inputs to facilitate preparation and fine-tuning can help improve the output quality.
- Task-Specific Vs. General Purpose: Decide whether the project necessitates a specific purpose or a broader range of applications. Choose domain-specific models mindfully and ensure alignment with your project requirements.
- Skillset: More complex LLMs may require deeper skill sets. In areas like data science, MLOps and NLP, some expertise within the team will be imperative, so evaluate if the team possesses the necessary capabilities or if any additional support is required.
Benefits of Open-Source LLMs for Startups
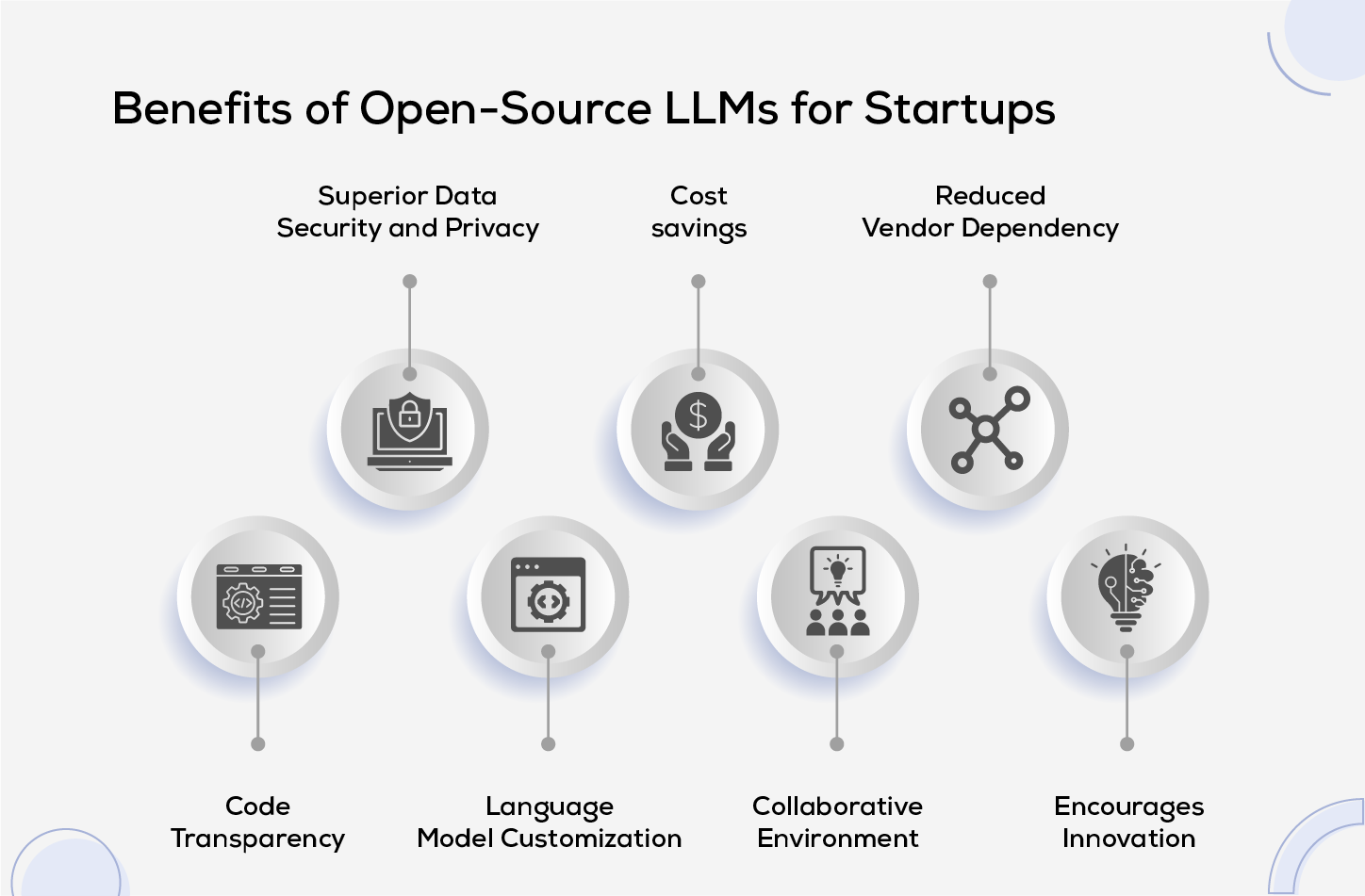
- Superior Data Security and Privacy: Open-source LLMs empower organizations to set up the model on their infrastructure, granting them greater oversight of their data.
- Cost savings: Open-source LLMs eradicate licensing fees, providing a cost-efficient solution for both enterprises and startups operating on limited budgets.
- Reduced Vendor Dependency: By embracing open-source LLMs, businesses diminish their reliance on a single vendor, fostering adaptability and averting the risk of vendor lock-in.
- Code Transparency: Open-source LLMs provide visibility into their underlying code, enabling organizations to scrutinize and verify the model's functionality.
- Language Model Customization: Customizing the model to suit specific industry or domain requirements becomes more feasible with open-source LLMs, allowing organizations to fine-tune the model according to their distinct needs.
- Collaborative Environment: Open-source projects often boast thriving communities of developers and experts, facilitating prompt issue resolution, access to valuable resources, and a collaborative environment for addressing challenges.
- Encourages Innovation: Open-source LLMs inspire innovation by empowering organizations to experiment and expand upon existing models. Particularly advantageous for startups, these models serve as a springboard for developing imaginative and distinctive applications.
The Most Popular Open-Source LLMs
We have compiled a summary of the top ten open-source LLMs. This list is based on the vibrant AI community and the machine learning repository, Hugging Face.
- GPT-NeoX-20B: GPT-NeoX- 20B developed by EleutherAI is one of the prominent open-source LLMs. It is an auto-aggressive language model that is designed upon the architecture of GPT-3. The model undergoes training on the Pile dataset, an open-source language modelling dataset totalling 886 gigabytes, which is further divided into 22 smaller datasets.
Both medium and large-scale businesses seeking advanced content generation can benefit from GPT-NeoX-20B. It efficient utilizes multi-GPU training, leading to faster training times and accelerated model convergence. It allows fine-tuning LLM on specific tasks, enabling adaptability across various applications. Furthermore, it has enhanced multi-lingual capabilities that comprehend and generate varied linguistic contexts.
- GPT-J-6B: GPT-J6B is also developed by EleutherAI. This is a transformer model pre-trained to generate human-like texts in response to prompts and is useful for tasks like story writing and even code generation. It is derived from the GPT-J model, featuring 6 billion trainable parameters reflecting its name. However, it is exclusively trained on English data, making it unfit for translation tasks or non-English language text generation.
This model can be suitable for startups and medium-sized businesses that wish to strike a balance between performance and resource consumption. It is not only accessible and easy to use for developers, but also affordable without needing huge infrastructure or expensive licenses.
-
BLOOM: Bloom is a multi-lingual language model by Big Science, designed to support a wider range of languages and dialects. It fosters scientific collaborations and breakthroughs. It boasts a massive 176 billion parameters and helps in text generation, summarization, embeddings, classification and semantic search.
Businesses that aim for a global audience with a varied range of languages can benefit from this model. Ethical communication and cultural sensitivity are paramount for Bloom. It is a responsible AI that restricts harmful content and has a low chance of producing culturally insensitive content. This AI-driven research and innovation can transform the landscape of scientific exploration and collaboration.
-
Llama 2: Developed by Meta AI and Microsoft, Llama is trained on publicly available online data sources. The fine-tuned model, called Llama Chat, uses instruction datasets that are available to the public and over 1 million human annotations. It comes in three different sizes - 7 billion, 13 billion, and 70 billion parameters - which makes it flexible and able to grow as needed.
Llama-2 offers superior scalability, efficiency and performance than Llama. It extends beyond chatbot application as it is proven to be highly useful in text summarization, generating responses to text and image inputs, content translation and generation, and coding. It can also be beneficial in the fields of research, education and entertainment.
-
CodeGen: CodeGen, developed by Salesforce AI Research is available in various sizes such as 350 million, 2 billion, 6 billion, and 16 billion parameters. As the name suggests, it outputs computer code, based on natural language prompts or existing code.
The diverse training dataset of CodeGen, sourced from programming languages and frameworks as well as h diverse training dataset, sourced from programming languages and frameworks as well as GitHub and Stack Overflow code snippets, enhances its ability to understand programming concepts and generate accurate code solutions from simple English prompts.
The potential of CodeGen to streamline software development and improve developer productivity has generated significant interest. CodeGen excels at detecting potential errors and mistakes in generated code, thereby enhancing code quality and reducing issues during execution.
-
BERT: BERT (Bidirectional Encoder Representations from Transformers), an early modern LLM, developed by Google on the Transformer Architecture, is one of the pioneering models in the field. Introduced in 2018, BERT emerged as an open-source LLM boasting up to 340 million parameters. Pre-trained on vast amounts of unlabelled text from sources like English Wikipedia and the Brown Corpus, BERT adopts a unique approach. This enables BERT to continuously improve through unsupervised learning from unlabelled text, even as it's deployed in practical applications like Google Search.
BERT understands the texts from both directions in a sentence. It relies on the Self-Attention mechanism that helps in comprehending relationships among the words in a sentence.
It uses Masked Language Modelling where words are defined by how they fit into the sentence, rather than having a fixed meaning on their own. It uses the Next Sentence Prediction technique to determine whether a given sentence logically follows the preceding one.
SEO specialists and content creators can benefit from BERT as it is useful in optimizing sites and content for search engines and improving content relevance.
-
T5 (Text-to-Text Transfer Transformer): T5 transformer-based architecture uses a text-to-text approach, offering 11 different sizes with the largest size consisting of 11 billion parameters. It is a versatile model that converts input text to output text, regardless of the specific task. Unlike traditional models that are designed for specific tasks like translation or summarization, T5 treats all tasks as text-to-text problems. It can handle a broad range of tasks by simply framing them as text-generation tasks.
T5 is pre-trained for tasks like translation, summarization and classification. It maintains contextual consistency and natural flow in lengthier interactions. As it was trained using the Colossal Clean Crawled Corpus (C4) dataset, it covers languages such as English, German, French and Romanian.
-
Falcon 40B and 180B: Technology and Innovation Institute of the United Arab Emirates launched a game-changing open source LLM-Falcon 40B. Falcon, licensed under the Apache License 2.0, is an autoregressive LLM crafted to produce text from prompts based on the RefinedWeb dataset. It is available for researchers and commercial users.
Falcon's outstanding performance and scalability make it particularly suited for larger enterprises seeking multilingual solutions such as website and marketing content creation, investment analysis, and cybersecurity.
The recent release of Falcon 180B by the TII, UAE has outshined Meta's Llama 2 and Google's PaLM 2 in various tasks like reasoning, coding, proficiency and knowledge tests. It is available for developers through a royalty-free license as per the Apache License 2.0. Falcon 180B supports English, German, Spanish and French as its primary languages, and offers limited functionality in Italian, Portuguese, Polish, Dutch, Romanian, Czech and Swedish.
-
Vicuna 33B: Vicuna-33B, developed by Large Model Systems (LMSys), covers a model size of 33 billion parameters. It is trained by fine-tuning Llama on user-shared conversations from ShareGPT and features a unique hybrid architecture merging transformer-based and biological neural network components. This blend enables it to match human-like language understanding while capitalizing on transformer model efficiency.
Vicuna-33B starts by using the transformer module to capture intricate syntactical subtleties in the input. Subsequently, the output undergoes refinement through the biological neural network, mimicking semantic comprehension similar to human cognition. Vicuna-33B stands out as a potent tool for natural language processing because it ensures comprehensive and contextually rich text generation.
Despite its size, Vicuna-33B is optimized for efficiency, promising fast responses to user queries without losing accuracy. Moreover, it can maintain context over longer stretches of text, allowing seamless handling of complex and multi-turn conversations.
-
OPT-175B: Meta’s Open Pre-Trained Large Language Model comprises a set of decoder-only pre-trained transformers, stretching from 125M to 175B parameters. OPT was trained on unlabelled text data primarily consisting of English sentences, enabling it to understand and generate human-like text across diverse domains.
It offers pre-trained models along with the codes needed to train and use the LLM. Pretrained models are handy for organizations lacking the computing power for training. Training neural networks requires a lot of resources, so using pre-trained models can help reduce the significant carbon footprint associated with training large networks.
Furthermore, it includes gradient checkpointing, reducing memory consumption by trading compute for memory. This assists in the training of larger models without memory constraints. OPT shines at few-shot and zero-shot learning, requiring minimal examples to learn new tasks or languages effectively.
Besides this, it also supports Automatic Mixed Precision (AMP) training, utilizing both single and half-precision to accelerate training and minimize memory usage. These features collectively contribute to improved performance and reduced resource requirements during training.
As the model is released under a non-commercial license, its access will be extended to academic researchers and individuals associated with governmental organizations, civil society, academia and industry research labs globally.
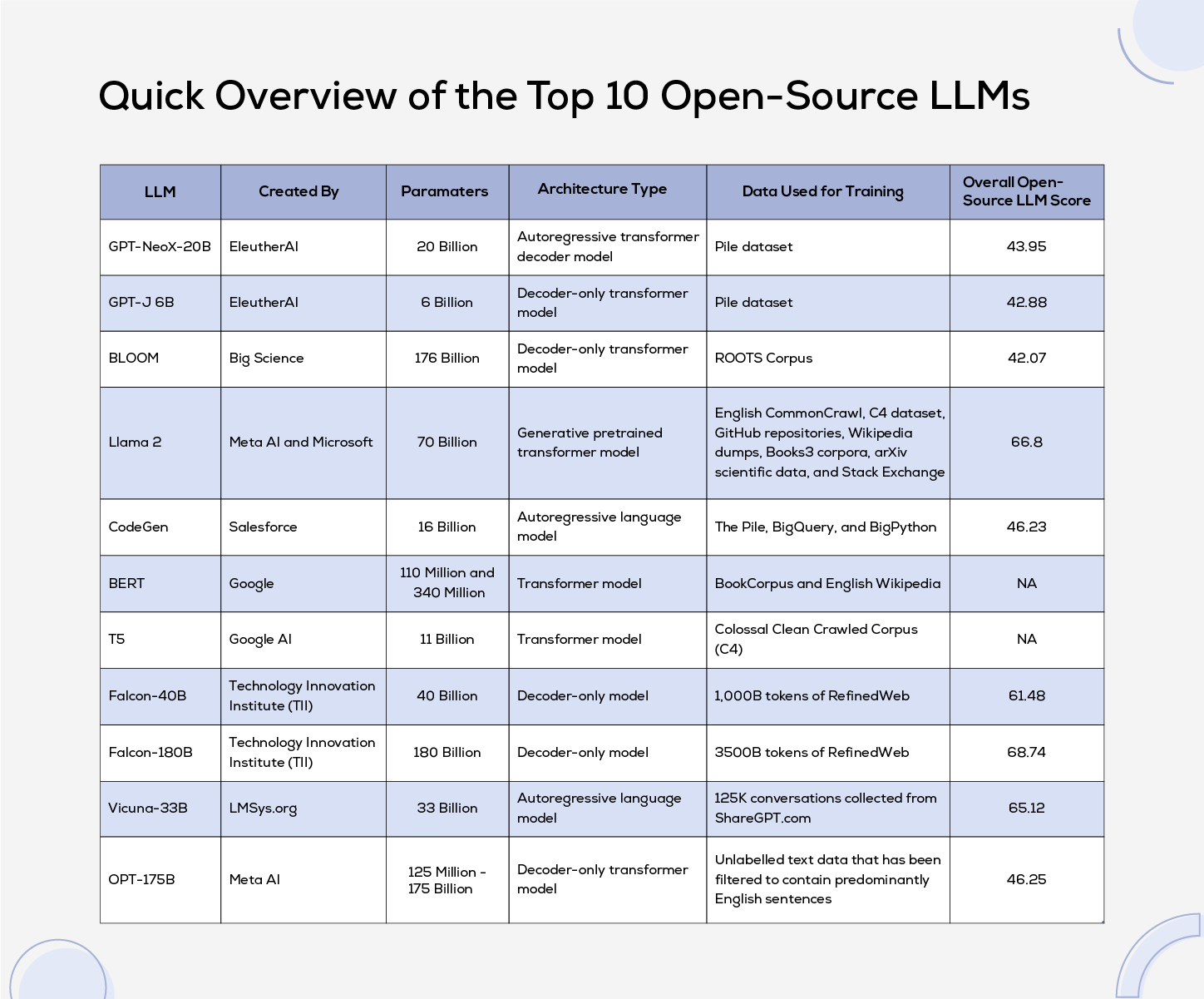
Quick Overview
Here's a concise overview showcasing the parameters, architecture type and training data of open-source LLMs. The scores listed in the table below are derived from the Hugging Face leadership board.
Conclusion
As we look forward to the horizon of AI-driven enterprises and startups, open-source LLMs emerge as the inspiration illuminating the path forward. Their resourcefulness and adaptability unlock a realm of possibilities, from revolutionizing natural language processing to trimming development expenses and nurturing collective ingenuity.
Yet, within this boundless potential lies the shadow of apprehension, with concerns regarding privacy, data security and the intricate process of fine-tuning to align with specific business needs.
In this futuristic landscape, partnering with a steadfast AI tech assistant becomes paramount. Together, they leverage the full range of possibilities while safeguarding against lurking risks, ensuring a future where innovation thrives, unhindered by the shadows of uncertainty.
Frequently Asked Questions
1. What is fine-tuning of LLM?
Fine-tuning an LLM refers to the process of further training the model on a specific task or dataset to improve its performance for that task.
2. Is Baichun 13B an open-source LLM?
Yes, Baichun 13B is an open-source LLM developed in China by Baichun.Inc. It’s pre-training datasets consist of 1.3 trillion tokens. It is useful in text generation, summarization, translation and many more tasks.
3. Where can we find open-source LLMs?
Open-source LLMs can be found on platforms like GitHub, Hugging Face and other AI model repositories.
4. Can all open-source LLMs used for commercial purposes?
Yes, in most cases, open-source LLMs can be used for commercial purposes, but it's essential to review the specific license terms of each model.
5. What are the limitations of open-source LLMs?
Some open-source LLMs may have the disadvantage of limited resources, security issues, integration challenges and IP concerns.




